The Expanded Othello AI Arena
Evaluating Intelligent Systems Through Constrained Adaptation to Unseen Conditions
You don't know how to win.
How many games will you need to figure out how to win?
The winning condition is hidden — this isn't standard Othello. No hints. Just play and figure it out.
The Challenge
When the Objective is Unknown
The capacity for rapid strategic adaptation to a novel, unseen environment is regarded as one of the major properties of artificial general intelligence (AGI). Novelty can take many forms — a new task, an unfamiliar geometry, or a changed set of rules. But one dimension remains central and largely unaddressed: the objective of the environment itself. If what counts as success is unknown, how should an AI — or a human — figure it out, and adapt quickly enough to the environment?
The difficulty lies in the nature of the signal. When the objective is unknown, the only evidence is the outcome — what happens at the very end of each attempt. Nothing along the way indicates whether a given approach is on the right track. This is compounded when the result is also shaped by another party — one whose responses to every decision further obscure the objective.
We propose the Expanded Othello AI Arena as a benchmark built around this challenge. It is not a test of how well an agent plays Othello. It is a test of how quickly one can identify a hidden objective and develop an effective strategy in an expanded, non-standard variant of Othello with undisclosed winning conditions.
The Environment: The Expanded Othello
Enviroment formalization and the design rationale
Evaluating how an AI discovers a latent objective requires going beyond what traditional meta-learning environments offer. Visual or structural variation — changes to inputs, layouts, or level appearances — leaves the fundamental rules of the environment intact. What is needed instead is an environment where the rules themselves change: where what counts as winning is not given, and must be inferred. Moreover, AGI demands more than single-agent adaptation. Deriving an objective from an environment that includes another agent — one whose actions are shaped by the same hidden rules — is a qualitatively harder and more realistic test of general intelligence.
We select Othello as the substrate for the environment to test such abilities because it satisfies these requirements. Its terminal state produces a continuous disc occupancy ratio ρ ∈ [0, 1] — making the winning condition directly parameterizable through a single threshold, and therefore variable in ways that go beyond structural change. It is zero-sum and adversarial by construction, requiring adaptation against an opponent whose decisions co-determine the outcome. And its flipping mechanics — high global state-change dynamics from simple local rules — mean that board geometry directly shapes which strategies are viable, making spatial layout a meaningful variable rather than mere decoration.
The environment space is therefore formalized as ℰ = ℒ × 𝒞. Each instance E = (L, C) is defined by two independently varying components. L is the board geometry — the size and shape of the board, along with the placement of non-interactive obstacles. It is fully observable, and represents the structural dimension of variation familiar from traditional meta-learning. C is the victory condition — latent and never directly revealed, it must be implicitly inferred through interaction. Leveraging Othello's natural disc occupancy ratio ρ, the winning criteria is varied across environments through a single parameterization K, which determines the threshold that separates victory from over-dominance draw conditions, i.e., the winning condition is not simply defined via majority of the discs; it has to stay in a specific ratio region, or strategic draw is often needed for prventing opponent win. For detailed definition of K, please refer to our paper.
The Benchmark
56 environments · 7 layouts × 8 win conditions
The goal of the benchmark is to measure how quickly an AI adapts to an environment with a latent objective — a capability we define as Skill-Acquisition Efficiency (SAE). To quantify this, we evaluate the performance an agent achieves when interacting with a given environment under a strictly limited number of interactions.
Concretely, the interaction budget per environment is fixed at 2,000 games. Within this budget, the agent learns through self-play by default; pre-training on prior environments is permitted. To enable systematic and quantified evaluation, we define a standard benchmarking suite of 56 environments — the Cartesian product of 8 victory conditions (C) and 7 board layouts (L) — designed to provide comprehensive coverage across diverse structural and objective-level challenges. The conditions are as follows:
Layout Space — 7 board geometries

Standard 8×8
8×8

No Corners
8×8

Partial C-Squares
8×8

X-Squares
8×8

Random Board 1
12×10

Random Board 2
6×8

Random Board 3
10×10
Condition Space — 8 victory conditions
Majority
More discs wins — standard Othello.
Win with majority, but disc ratio must stay below 80%.
Narrow window — ratio must land between 50% and 60%.
Standard rules with a hard turn limit.
Minority
Fewer discs wins — inverse Othello.
Win with minority, but disc ratio must stay above 40%.
Win with minority, but disc ratio must stay above 20%.
Inverse rules with a hard turn limit.
How to Use
Installation & Quick Start
Please check Environment for the detailed guidelines.
Installation
# Install directly from GitHub pip install git+https://github.com/blakeyoo/ExpandedOthello-AEC.git
Requires Python ≥ 3.9 · numpy · numba · pettingzoo · gymnasium
Load a Benchmark Environment
56 preset environments are available — the Cartesian product of 7 board layouts and 8 win conditions.
from expanded_othello import load_preset # Load one of 56 official environments (index 0–55) env = load_preset(0) obs, _ = env.reset() while env.agents: agent = env.agent_selection action_mask = obs["action_mask"] action = your_agent.act(obs, action_mask) env.step(action) obs, reward, term, trunc, _ = env.last()
Custom Environment
Define your own board geometry and win condition beyond the preset suite.
from expanded_othello import make_env env = make_env( board_size=(10, 10), obstacles=[(0, 0), (9, 9)], win_cond=0.6, n_turns=-1, )
Possible Approaches
What works, what doesn't, and where the open problems are
To demonstrate the benchmark's utility, we introduce a neuroevolutionary Adaptive Minimax as a foundational baseline. It combines two components: a population of positional value networks meta-evolved across diverse board layouts (PosNet), providing spatial priors that transfer to unseen geometries; and an adaptive utility-weighting mechanism that evolves within each environment to infer the latent winning condition (WeightNet). Together, they allow the agent to adapt both spatially and strategically from terminal outcomes alone.
In broad regimes — standard, inverse, and blitz conditions — the Adaptive Minimax converges rapidly, often reaching high win rates within the first generation of updates. Notably, it achieves win rates comparable to MCTS-100 despite MCTS having direct simulator access to the latent threshold K during search. The contrast with PPO is stark: trained under the same 2,000-game budget, PPO's win rate curves plateau early and remain largely flat — sparse terminal rewards provide insufficient gradient signal for meaningful adaptation within the budget, even when training is extended to 10,000 games.
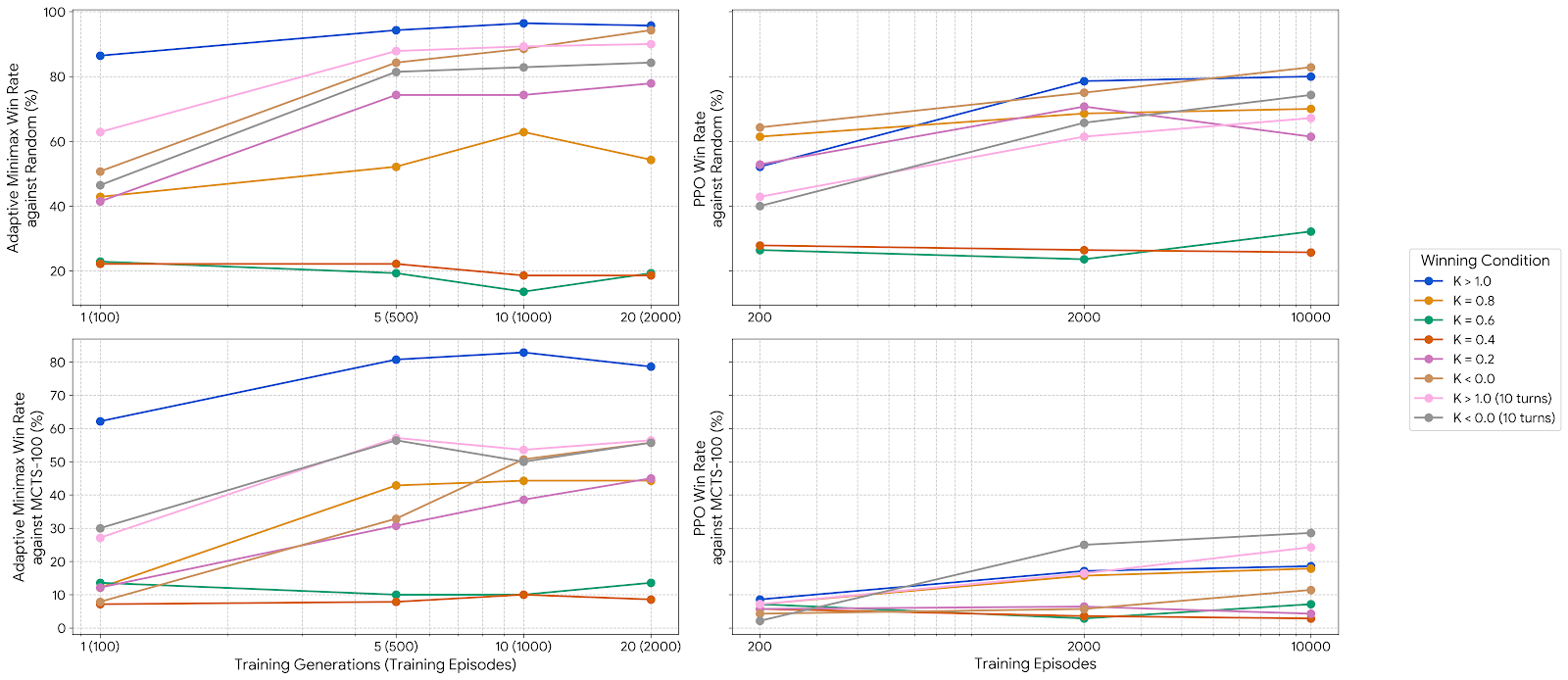
Where the Adaptive Minimax falls short is in narrow-interval regimes: at K = 0.6 and K = 0.4, win rates collapse and outcomes are dominated by draws. The agent learns to avoid losing, but cannot control its terminal disc ratio with the precision required to enter the admissible interval consistently. These regimes remain an open challenge for all tested approaches.
Adaptive Minimax
averaged over 7 layouts per condition · trained with 2,000 games of self-play per environment
Adaptive Minimax results are averaged across layouts after 2,000 training episodes (trained with terminal game outcomes alone). Full per-layout breakdown available in the paper.
PPO
averaged over 7 layouts per condition · trained with 2,000 games of self-play per environment
PPO results are averaged across layouts after 2,000 training episodes (trained with terminal game outcomes alone). Full per-layout breakdown available in the paper.
These results demonstrate that the Arena captures two qualitatively distinct adaptation challenges: rapid win-oriented convergence in broad regimes, and fragile, draw-heavy occupancy control in narrow ones. The difficulty gradient exposed here — and the failure of all tested baselines in the narrowest regimes — points to open research problems the Arena is specifically designed to surface.